PyTorch中的nn.Conv1d与nn.Conv2d
本文共 2583 字,大约阅读时间需要 8 分钟。
一维卷积nn.Conv1d
一般来说,一维卷积nn.Conv1d用于文本数据,只对宽度进行卷积,对高度不卷积。通常,输入大小为word_embedding_dim * max_length,其中,word_embedding_dim为词向量的维度,max_length为句子的最大长度。卷积核窗口在句子长度的方向上滑动,进行卷积操作。
定义
class torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
主要参数说明:
- in_channels:在文本应用中,即为词向量的维度
- out_channels:卷积产生的通道数,相当于是将词向量的维度从in_channels变成了out_channels
- kernel_size:卷积核的尺寸;卷积核的第二个维度由in_channels决定,所以实际上卷积核的大小为kernel_size * in_channels
- padding:对输入的每一条边,补充0的层数
代码示例
输入:批大小为32,句子的最大长度为35,词向量维度为256 目标:句子分类,共2类conv1 = nn.Conv1d(in_channels=256, out_channels=100, kernel_size=2)input = torch.randn(32, 35, 256)input = input.permute(0, 2, 1) # (32, 35, 256) => (32, 256, 35)output = conv1(input) # (32, 100, 34)
要使用permute是因为nn.Conv1d是对输入的最后一个维度卷积,所以要把句子长度所在的那个维度变换到最后。
上面的代码只使用了一个卷积核,如果要使用多个卷积核应该使用nn.ModuleList和for循环。
import torchimport torch.nn as nnwindow_sizes = [2,3,4]convs = nn.ModuleList([ nn.Sequential(nn.Conv1d(in_channels=8, out_channels=4, kernel_size=h), nn.ReLU()) for h in window_sizes ])embed = torch.randn(2, 16, 8)embed = embed.transpose(1,2)output = [conv(embed) for conv in convs]#print(output)for x in output: print(x.size())'''输出torch.Size([2, 4, 15])torch.Size([2, 4, 14])torch.Size([2, 4, 13])'''
二维卷积nn.Conv2d
一般来说,二维卷积nn.Conv2d用于图像数据,对宽度和高度都进行卷积。
定义
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
代码示例
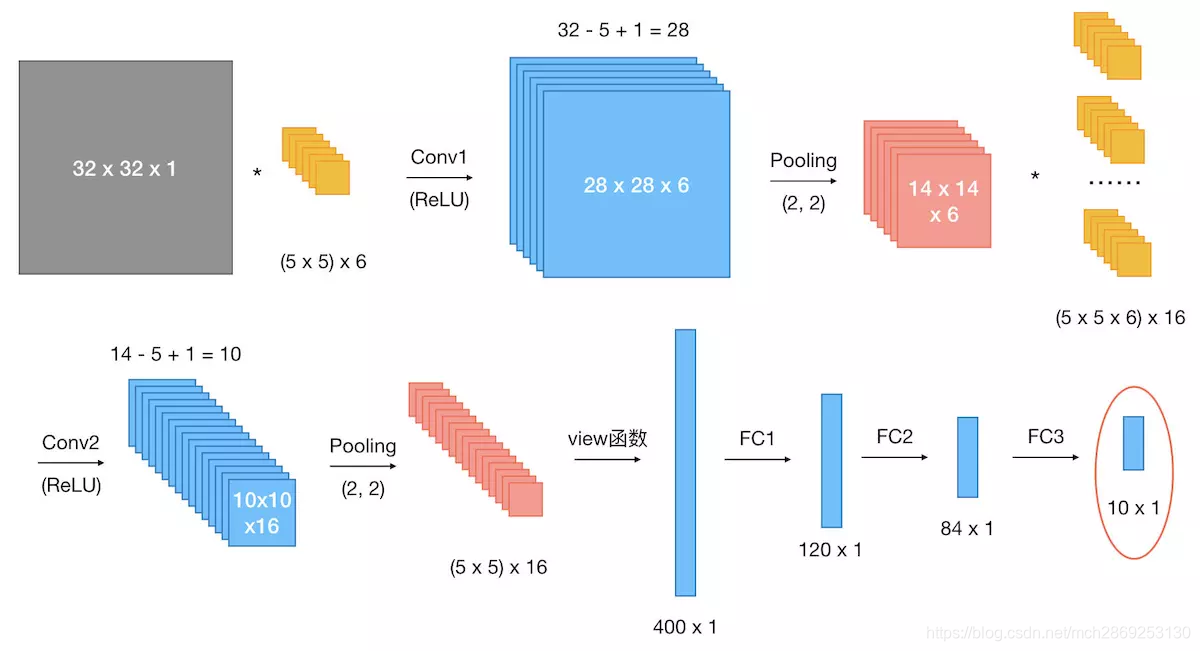
假设现有大小为32 x 32的图片样本,输入样本的channels为1,该图片可能属于10个类中的某一类。CNN框架定义如下:class CNN(nn.Module): def __init__(self): nn.Model.__init__(self) self.conv1 = nn.Conv2d(1, 6, 5) # 输入通道数为1,输出通道数为6 self.conv2 = nn.Conv2d(6, 16, 5) # 输入通道数为6,输出通道数为16 self.fc1 = nn.Linear(5 * 5 * 16, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self,x): ''' 总共有2个卷积层,每一层的结构都是卷积->relu->max_pool ''' # 第一层 x = self.conv1(x) # 32*32*1 => 28*28*6 x = F.relu(x) x = F.max_pool2d(x, 2) # 28*28*6 => 14*14*6 # 第二层 x = self.conv2(x) # 14*14*6 => 10*10*16 x = F.relu(x) x = F.max_pool2d(x, 2) # 10*10*16 => 5*5*16 # view函数将张量x变形成一维向量形式,总特征数不变,为全连接层做准备 x = x.view(x.size()[0], -1) # 5*5*16 => 400*1 x = F.relu(self.fc1(x)) # 400*1 => 120 * 1 x = F.relu(self.fc2(x)) # 120*1 => 84*1 x = self.fc3(x) # 84*1 => 10*1 return x
转载地址:http://qwrn.baihongyu.com/
你可能感兴趣的文章
Manjaro 24.1 “Xahea” 发布!具有 KDE Plasma 6.1.5、GNOME 46 和最新的内核增强功能
查看>>
mapping文件目录生成修改
查看>>
MapReduce程序依赖的jar包
查看>>
mariadb multi-source replication(mariadb多主复制)
查看>>
MariaDB的简单使用
查看>>
MaterialForm对tab页进行隐藏
查看>>
Member var and Static var.
查看>>
memcached高速缓存学习笔记001---memcached介绍和安装以及基本使用
查看>>
memcached高速缓存学习笔记003---利用JAVA程序操作memcached crud操作
查看>>
Memcached:Node.js 高性能缓存解决方案
查看>>
memcache、redis原理对比
查看>>
memset初始化高维数组为-1/0
查看>>
Metasploit CGI网关接口渗透测试实战
查看>>
Metasploit Web服务器渗透测试实战
查看>>
MFC模态对话框和非模态对话框
查看>>
Moment.js常见用法总结
查看>>
MongoDB出现Error parsing command line: unrecognised option ‘--fork‘ 的解决方法
查看>>
mxGraph改变图形大小重置overlay位置
查看>>
MongoDB可视化客户端管理工具之NoSQLbooster4mongo
查看>>
Mongodb学习总结(1)——常用NoSql数据库比较
查看>>